Texel provides a powerful mechanism to search for duplicates in the songs. It tries to detect duplicates by
examine the tags and compare artist, title and upon request album information.
To start the duplicate detectio use either the button
![]() in the toolbor or choose - from the menu.
You will get the following dialog:
in the toolbor or choose - from the menu.
You will get the following dialog:
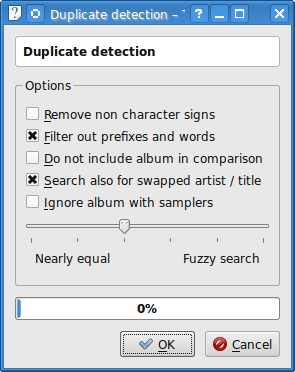
Computation of the duplicates is done on all available cores. here is no way to limit the usage of cores. Therefore the machine will not be very responsive while doing the computation. However, doubling the cores does nearly half the execution time and does therefore help for a fast result.
Texel does provide a fuzzy duplicate detection. To reach this fuzziness three different functionalities can be combined. First, instead of examine the original strings a stripped version is used. In the stripped version superflous words are removed as well as special characters and whitespaces. This normalization process allows simplified versions of names and allows to compare e.g. “The Beatles” and “Beatles”. The “The” at the beginning of the artist is removed in this step. You can turn it on by enabling the option Filter ot prefixes and words. You may choose Remove non character signs to remove everything except letters and number for comparison (note that this is only done for comparison and not in the tags themselves!). The second step is executed while comparing the resulting strings. A distance between two strings is calculated; this distance (called the Levensthein distance) are the number of minimum changes to reach the second string from the first one. A change may either be an additional character, a changed character, a removed character or two swapped characters. The slider which defines the fuzziness of the search sets the allowed comparsion distance of two string from 0 (exact strings) to 5 (up to five different characters). Please note that at most two changes in sequence are accepted from the comparison, otherwise the strings are considered as different. The third step is that also flipped artist and title may be examined as often these values are swapped and therefore duplicates are not detected. As duplicate detection is fast (even with more than 10.000 tags a matter of a few minutes or seconds) you can safely include this option Search also for swapped artist/title.
Note
Please note that the more fuzzy the search is the more potential duplicates are detected which are simply other titles.
The result of the duplicate detection is shown in the vertical header of the main table. When the duplicate detecion icon appears for a row potential duplicates exist. These are shown in the tooltip of the icon. However, to have a more specific overview of potential duplicates use the grouping and filtering mechanisms provided in the menu. You can also turn on the duplicate helper dock which displayes all possible dulicates for a tag in a list.
The duplicate detection compares always against all tracks which are currently loaded into memory. However, it is possibe to restrict the set of items to compare. Simple do a selection of complete rows or apply a filter to limit the number of displayed items. A new checkbox Compare selected against all tracks is enabled and checked. This limits the detection to only the filtered/selected items. When a selection exists this is taken, also when a filter is applied.